
Benchmarked testing of the DDN Data Intelligence Platform with the NVIDIA DGX™-B200 system over Ethernet demonstrates:
- A single DDN AI400X2-Turbo achieves 10x our usual minimum requirement of 1 GB/s/GPU for read and write operations, paired with a NVIDIA DGX-B200
- Multiple DDN AI400X2-Turbo appliances deliver up to 96% network utilization per DGX-B200, saturating nearly 100 GB/s (800 Gbps) of bandwidth in both read and write operations.
- Adversarial benchmarks using unmodified competitor-written code to simulate AI workloads (mixed read and random read) still achieve up to 7x the usual minimum 1 GB/s/GPU requirement with a single DDN AI400X2-Turbo paired to a NVIDIA DGX-B200.
- The obtained peak performance provides a 90% margin for efficiency loss while still maintaining the usual 1 GB/s/GPU target, giving us extremely high confidence that at-scale performance will remain aligned with our requirements.
These results underscore the extreme efficiency of DDN AI Storage solutions paired with NVIDIA DGX-B200 systems, which are perfectly suited to handle peak performance needs for AI workloads at a per-client granularity while scaling seamlessly for large cluster deployments, therefore handling AI at any scale.
Single DDN AI400X2-Turbo paired with a NVIDIA DGX-B200
Storage performance needs can be uneven in artificial intelligence workloads. This can stem from factors like mixed workloads or optimization techniques (e.g., model parallelism) in the workload itself, or from the system’s limited scale. In such conditions, the overall performance across multiple clients might not fully reflect the actual contention occurring at a per-node granularity.
The DDN EXAScaler parallel file system avoids traditional bottlenecks caused by single-server communication limits. Clients can seamlessly read and write data to all DDN servers simultaneously in parallel, asynchronously, without introducing inter-server communication bottlenecks. Put simply, the per-client performance of DDN EXAScaler is exceptional, allowing users to fully utilize the performance of DDN AI appliances at any scale.
Benchmarking Details & Results
To validate this capability, we tested the following configuration with the NVIDIA DGX-B200 over Ethernet (RoCEv2):
- A single NVIDIA DGX-B200 system
- A single DDN AI400X2-Turbo
- NVIDIA SN5600 (Spectrum-4) switch
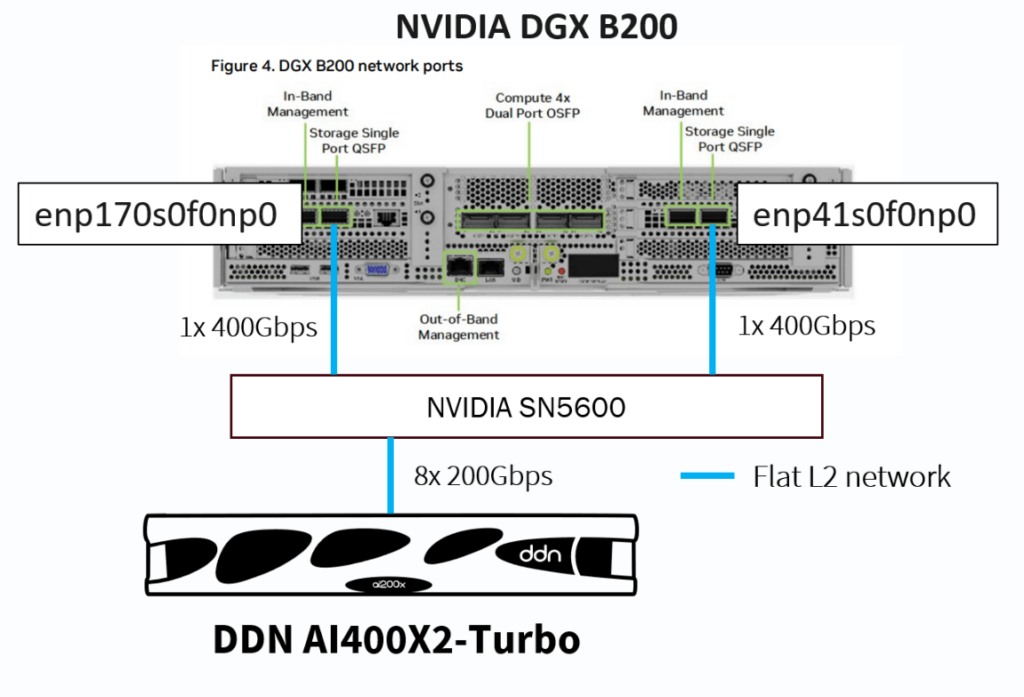
The connection made between the NVIDIA DGX-B200 system and the SN5600 follows the default NVIDIA recommendation. The first two ports of each NVIDIA BF3 DPUs on the NVIDIA DGX-B200 are used for storage (enp41s0f0np0 and enp170s0f0np0, in DGX OS7). The two links’ aggregated bandwidth is 100 GB/s (800 Gbps, 400 Gbps per link).
On the other side, the DDN AI400X2-Turbo is using the out-of-box configuration, connecting to the same SN5600 switch through 8× 200 Gbps links using ConnectX-7 adapters.
On the switch, the networking configuration is a simple flat L2 network configured for RoCEv2 using jumbo frames, but without Spectrum-X, support for which will be added in the future for the next-generation DDN platform (AI400X3; see ” Message from DDN” to learn more about the improvements provided by Spectrum-X).
The workload employed to measure the peak performance is the flexible I/O tester (fio), developed by the Linux kernel block device maintainer, used through our internal fio launcher.
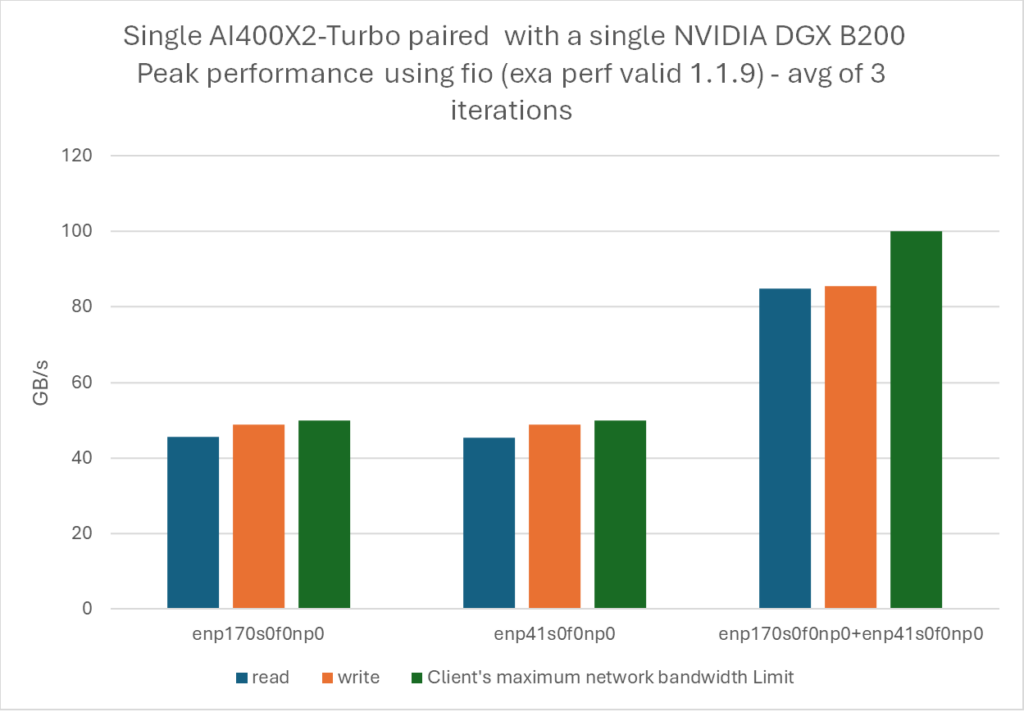
Three different tests were done for both read and write operations, measuring each NVIDIA BF3-DPU separately (two tests) and conjointly (third test).
The peak per-link performance we obtained demonstrates, for both read and write operations, over 90% bandwidth utilization. Using two links to access DDN EXAScaler achieves over 85 GB/s for both read and write operations, 10 times exceeding our minimum recommendation of 1 GB/s, and this while using a single client-server pair, allowing for extreme performance at minimal granularity.
Multiple DDN AI400X2-Turbo paired with a NVIDIA DGX-B200 system
While a single DDN AI400X2-Turbo paired with a NVIDIA DGX-B200 already exceeds by 10x the usual 1 GB/s/GPU target for both read and write operations, adding more DDN AI400X2-Turbo systems scales performance even further, not only for large-scale deployments but also at the minimal granularity of a single node, delivering up to 96% storage network utilization, and ensuring full hardware efficiency.
Benchmarking details & results
To validate this capability, we tested the following configuration with the NVIDIA DGX-B200 system over Ethernet (RoCEv2):
- A single NVIDIA DGX-B200
- Two DDN AI400X2-Turbo
- NVIDIA SN5600 (Spectrum-4) switch

This configuration mirrors the single-DDN-AI400X2-Turbo test described earlier, with the only difference being the addition of a second DDN AI400X2-Turbo appliance. The same fio tests were run on this setup.
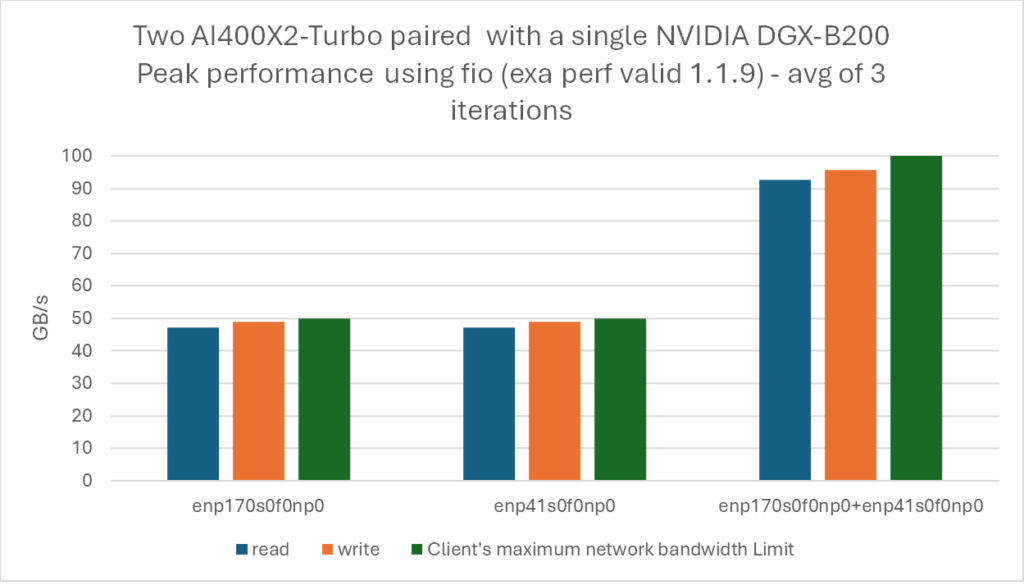
Compared to the single DDN AI400X2-Turbo configuration, deploying multiple appliances allows the NVIDIA DGX-B200 to achieve peak performance at a new high, with 96% network bandwidth utilization and 98% scalability efficiency per link.
Adversarial benchmarks using competitor-written code
While peak performance enables upper-bound comparisons between storage systems, regardless of the test chosen, we also measured our performance using competitor-written code to provide even more trustworthy results, but also because this test simulates AI like workloads, making it slightly less synthetic than previous peak-performance experiments.
Using CoreWeave’s publicly available ioperftest scripts (https://github.com/coreweave/ioperftest.git), we executed their FIO workload sweeps, with the only modification being provided there:

The following result was obtained using the single AI400X2-Turbo setup described above.
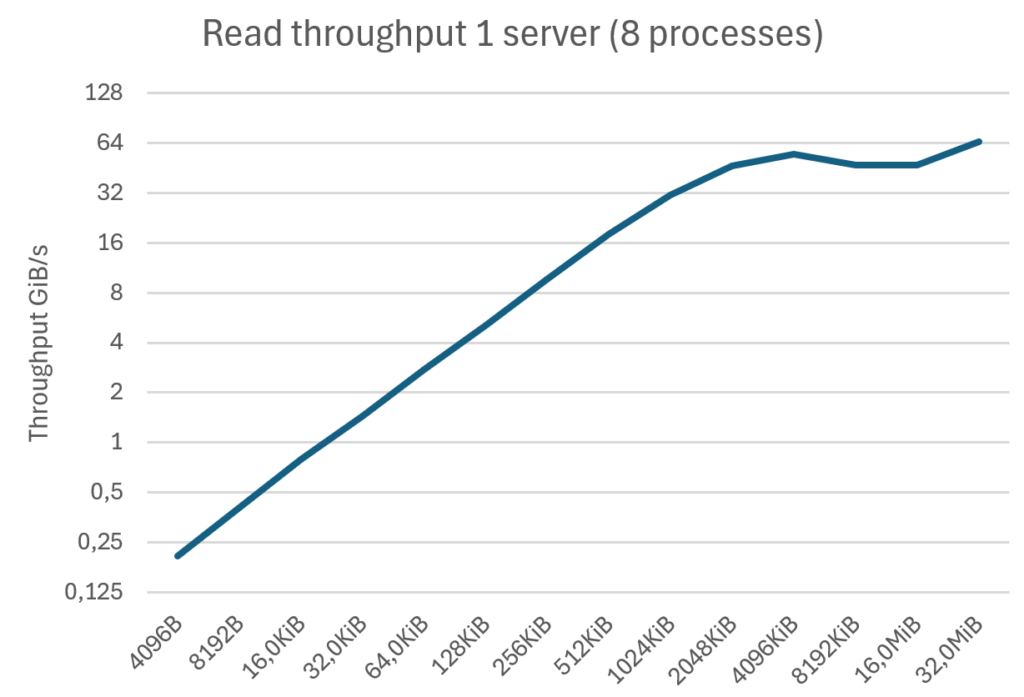
This result, measured in GiB/s, demonstrates an up-to 7x increase over our target of 1 GB/s per GPU, and meets/exceeds the 1 GB/s target starting from a minimal block size of 256 KiB.
Extrapolation at scale
This series of tests has demonstrated up to nearly perfect efficiency of DDN Data Inteliggence Patform for the NVIDIA DGX-B200. At scale, we can extrapolate the performance delivered for multiple NVIDIA DGX-B200 nodes based on per-node efficiency metrics. By varying efficiency from 1% to 100% and using the two previously validated workloads as the baseline for 100% efficiency, we can directly state:
- Even at only 10% efficiency retained at scale, the 1 GB/s per node target is consistently met when using peak performance as the baseline (84GB/s).
- For adversarial benchmarks (59GB/s), 18% efficiency is the minimum required to align with our performance threshold.

These two results allow us an 82% margin of efficiency drop before reaching sub-1 GB/s/GPU performance, giving us extremely high confidence in our performance at scale using the NVIDIA DGX-B200. To learn more, read the reference architecture.
To learn more, read the reference architecture.